


¿Qué es la disponibilidad?
La disponibilidad es una forma de medir la durabilidad de un sistema. La disponibilidad puede definirse como el tiempo que un sistema está realmente funcionando (o en servicio), dividido por el tiempo que el sistema podría haber estado funcionando.
¿Cuáles son los niveles de disponibilidad típicos?
 Los sistemas suelen segmentarse en niveles de disponibilidad por su número de "nueves", y se describen con más detalle utilizando términos como "altamente disponible" y "tolerante a los fallos.” Si un sistema está disponible el 99% de las veces (dos nueves), eso significa que no está disponible el 1% de las veces. En un año cualquiera con 525.600 minutos disponibles, puedes esperar que un sistema de "dos nueves" esté caído durante 5256 de esos minutos, o durante unas 88 horas o 4 días. Dependiendo de su particular costo del tiempo de inactividadesto puede ser caro.
Los sistemas suelen segmentarse en niveles de disponibilidad por su número de "nueves", y se describen con más detalle utilizando términos como "altamente disponible" y "tolerante a los fallos.” Si un sistema está disponible el 99% de las veces (dos nueves), eso significa que no está disponible el 1% de las veces. En un año cualquiera con 525.600 minutos disponibles, puedes esperar que un sistema de "dos nueves" esté caído durante 5256 de esos minutos, o durante unas 88 horas o 4 días. Dependiendo de su particular costo del tiempo de inactividadesto puede ser caro.
| Disponibilidad | Número de nueves | Tiempo de inactividad por año | A menudo se describe como |
|---|---|---|---|
| 99.9% | Tres nueves | 526 minutos o menos | Disponible en |
| 99.99% | Cuatro nueves | 53 minutos o menos | Muy disponible |
| 99.999% | Cinco nueves | 5 minutos o menos | Tolerancia a las fallas |
Los sistemas que funcionan con niveles de disponibilidad medios más altos de "cuatro nueves" y "cinco nueves" suelen denominarse sistemas de "alta disponibilidad" o "tolerantes a las fallas".
¿Qué métodos se utilizan comúnmente para aumentar la disponibilidad?
Existen varios métodos de eficacia probada que las empresas utilizan para mejorar la disponibilidad, que van desde la mejora de la fiabilidad y la capacidad de recuperación del sistema, pasando por la aplicación de procedimientos de copia de seguridad y recuperación, hasta el despliegue de clústeres redundantes (físicos o virtuales) con servicios de conmutación por error.

Robusto, sin ventilador, con clasificación IP-40
Usando sistemas fiables y resistentes
Una forma de mejorar la disponibilidad es utilizar sistemas más fiables. Cuanto más robusto y fiable sea su sistema, menos probabilidades hay de que se averíe. Cuanto menos se rompa, más tiempo seguirá funcionando, y por definición, más tiempo estará disponible.
Una forma relacionada de aumentar la disponibilidad es implementar un sistema más resistente, que pueda recuperarse rápidamente de un contratiempo. Al reducir el tiempo necesario para reparar el sistema y reanudar los servicios, se reduce el tiempo de inactividad y se aumenta la disponibilidad general. Lo que es interesante es que si un sistema puede recuperarse rápidamente cada vez, entonces importa menos la frecuencia con la que se rompe.
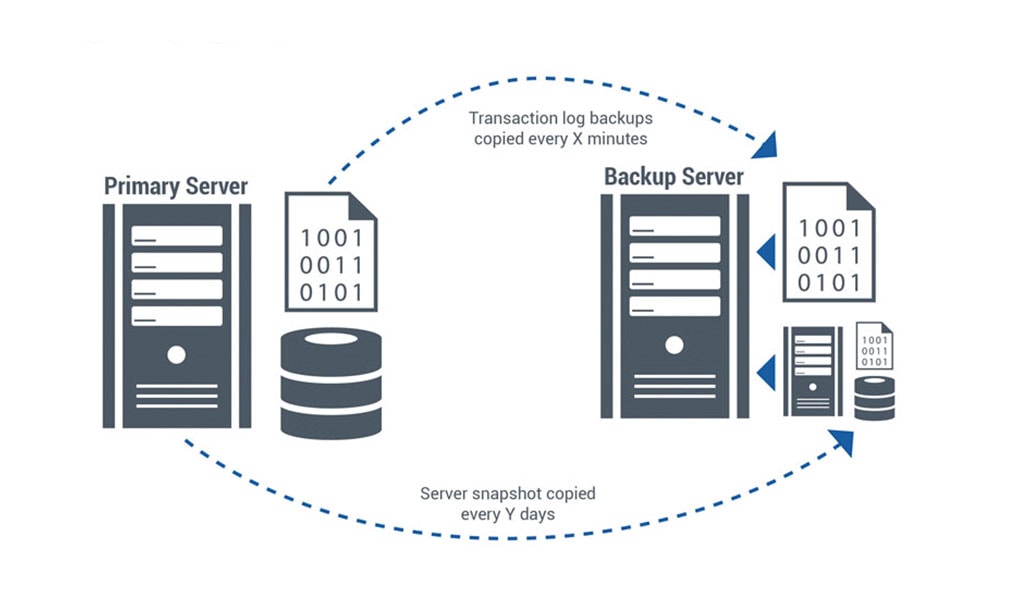
Implementación de la copia de seguridad y la recuperación
Sin embargo, la fiabilidad y la resistencia tienen sus límites. En muchos casos, no es sólo la disponibilidad del sistema, sino también la protección y la integridad de los datos lo que debe preocuparte.
Las empresas que adoptan un enfoque más holístico de la disponibilidad suelen hacer copias de seguridad de sus datos de forma regular y mantienen sistemas de repuesto en el inventario. Si sus sistemas de producción experimentan un fallo catastrófico, reinician los servicios de sus sistemas de repuesto, recuperando los datos que necesitan de sus archivos.
Establecer servicios de respaldo y recuperación requiere cierta habilidad. Y el tiempo de recuperación puede variar, desde unas pocas horas hasta unos pocos días, dependiendo de las aplicaciones, la cantidad de datos y la disponibilidad de piezas de repuesto.
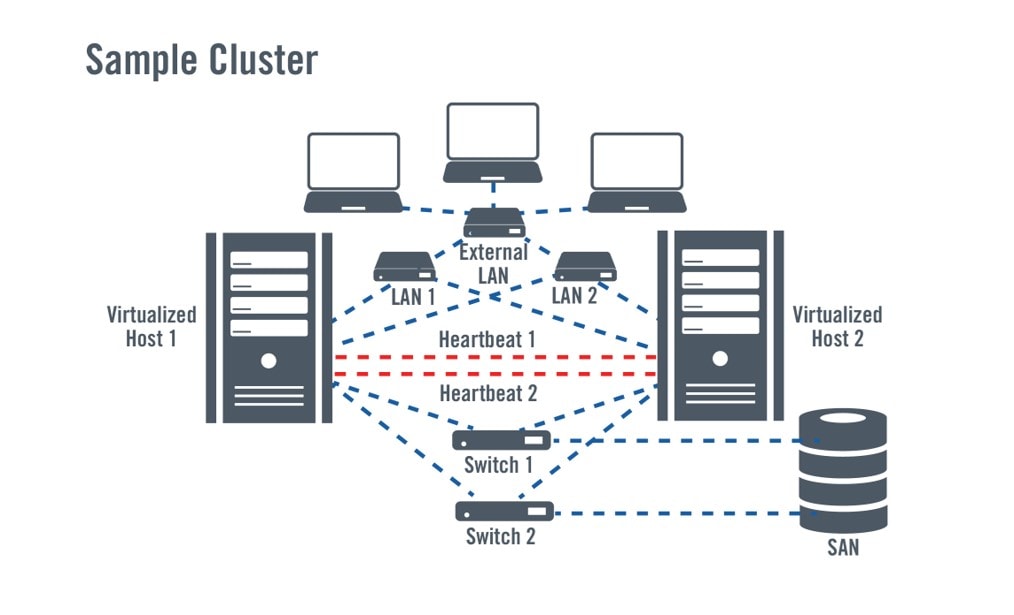
Usando servicios de clustering y failover nativos y virtuales
Para algunas empresas, puede ser aceptable reanudar los servicios después de unas horas o unos días. Pero las que tienen mayores costos relativos de inactividad necesitan un enfoque más resistente, tanto para sus aplicaciones como para sus datos.
La agrupación y la conmutación por error utiliza el mismo principio que la copia de seguridad y la recuperación, pero acorta el tiempo de recuperación de los servicios haciendo algunas cosas por adelantado, como replicar los sistemas para que estén listos para reanudar en un momento dado. Se combinan varios sistemas y los datos son compartidos por estos sistemas redundantes. Por lo general, un sistema actúa como el principal, proporcionando a los usuarios acceso a las aplicaciones y a los datos, mientras que un sistema secundario actúa como respaldo, ya sea permaneciendo inactivo hasta que se necesite (pasivo) o ejecutando otras aplicaciones (activo). En caso de que se produzca un fallo en el sistema primario, la aplicación se "conmuta" al sistema secundario y vuelve a funcionar en él, siempre que se establezcan las conexiones con los datos compartidos.
Con la aparición de las tecnologías de virtualización, los conceptos de agrupamiento y conmutación por error se han ampliado a los sistemas virtuales. Hoy en día, las tecnologías de virtualización y agrupación se utilizan para combinar sistemas físicos y aplicaciones de conmutación por error que se ejecutan en máquinas virtuales (VM), aprovechando la portabilidad de las VM.
¿Qué ofrece Stratus ?
Stratus ofrece una amplia variedad de edge computing soluciones que cubren todo el espectro de la disponibilidad. Desde productos sólo de software como everRunhasta soluciones completas como ztC Edge y ftServer que incluyen hardware, software y servicios, Stratus ayuda a los clientes a ofrecer de forma fácil y asequible cargas de trabajo de alta disponibilidad y tolerancia a fallos.